0%
去中心化(Fully decentralized)
- 每个Agent独立和环境交互,并且用自己的观测和奖励来更新自己的策略。
介绍

- 每个Agent都是独立的个体,互相不沟通交流。
- 每个Agent都独立和环境交互,获取o和r。
- 每个Agent都有自己的策略网络。独立训练自己的策略网络,和单智能体强化学习一样。
- 本质还是单智能体强化学习。
去中心化AC
- 第i个智能体拥有一个策略网络(actor):$π(a^i|o^i;\theta^i).$
- 第i个智能体拥有一个价值网络(critic):$q(o^i|a^i;w^i).$
- Agent之间不共享观测和动作。
- Actor网络和Critic网络的训练方式和单智能体一样。
完全中心化(Fullt centeralized)
- 所有agent都把信息传给中央控制器,中央控制器知道每个Agent的观测和奖励。Agent没有策略网络,自己不做决策,决策都由中央做。
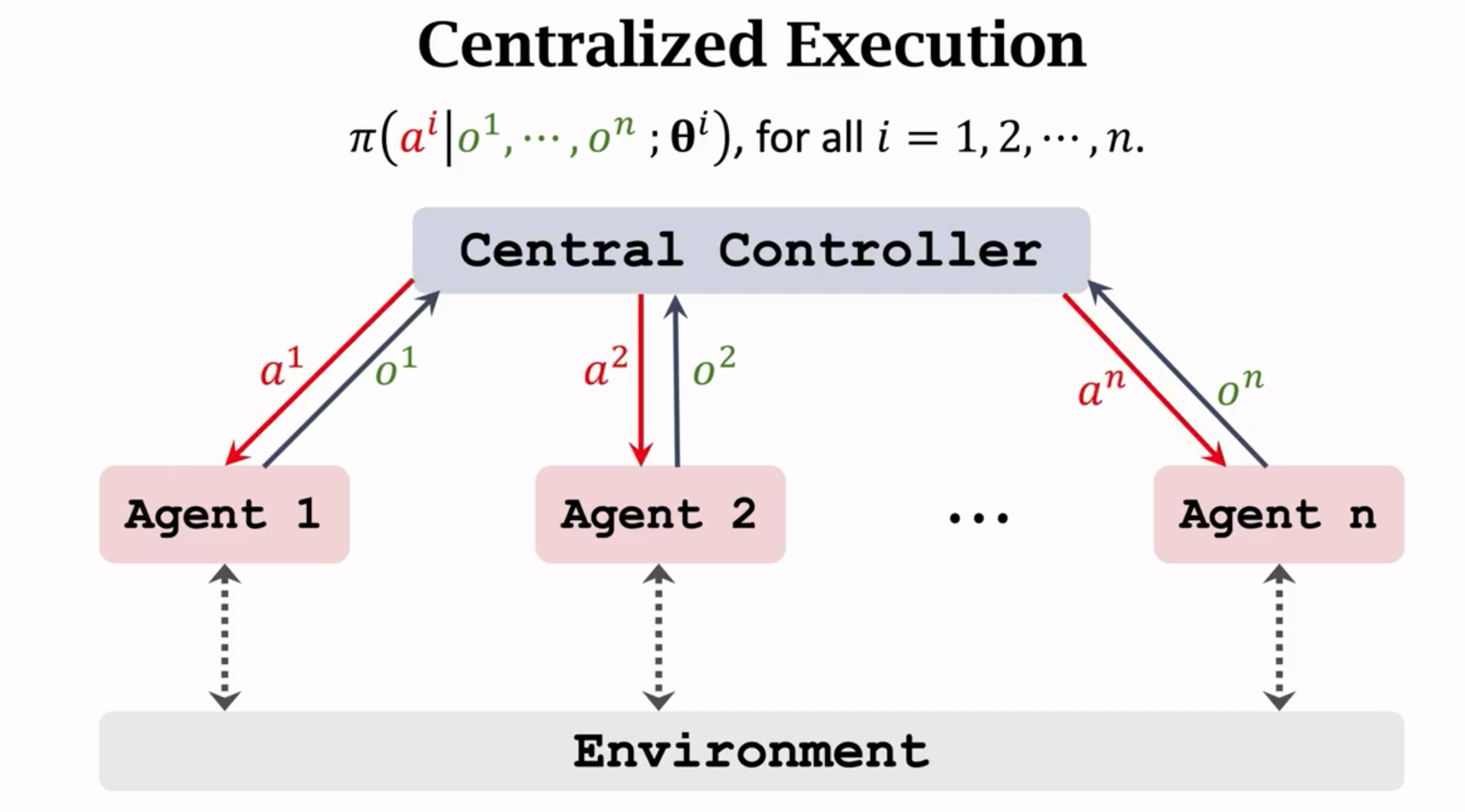
- Agent上没有策略网络,不能自己做决策。
- 每个Agent把自己的观测上传给中央,中央作出决策后发送给每个Agent。
中心化AC
- 让 $a=[a^1,a^2,…a^n]$ 表示所有Agent的动作。
- 让 $o=[o^1,o^2,…o^n]$ 表示所有Agent的观测。
- 中央控制器知道所有的a,o和所有的奖励。
- 中央控制器拥有n个策略网络和那个价值网络:
- 第i个Agent的策略网络:$π(a^i|o;\theta^i).$
- 第i个Agent的价值网络:$q(o|a;w^i).$
- 训练完全由中央控制器执行:
- 使用策略梯度来训练策略网络。
- 使用TD算法来训练价值网络。
- 训练技术后,中央控制器用策略网络做决策:
- 对于每个Agent,每个Agent把自己的观测$o^i$上传给中央。
- 中央知道 $o=[o^1,o^2,…o^n]$ 。
- 对于全部Agent,中央从第i个策略网络$a^i~π(\cdot|o;\theta^i)$随机抽样一个动作$a^i$并发送给第i个Agent。
总结
- 好处:知道全局信息,可以更好的做决策。
- 缺点:决策慢。决策过程需要通信,无法做到实时的决策。
中心化训练,分布式执行(Centeralized tarining with decentralized execution)
- Agent各自有各自的策略网络。
- 中央控制器帮助Agent训练策略网络。
- 训练结束后每个Agent根据自己的策略网络做决策,不需要和中央控制器通信。
介绍
- 每个Agent拥有自己的策略网络(actor):$π(a^i|o^i;\theta^).$
- 中央控制器上有n个价值网络(critic):$q(o|a;w^i).$
- 中心化训练:训练期间,中央控制器知道每个Agent的观测,动作和奖励。
- 分布式执行:训练结束后,每个Agent独立做决策。不需要中央控制器。

- 每个Agent作出动作$a^i$与环境$o^i$交互,得到$r^i$,训练时讲动作,观测和奖励全部上传到中央。

- 中央控制器上有所有Agent的动作,环境和奖励。
- 中央控制器训练所有的Critic,$q(o|a;w^i).$
- 更新$w^i$,使用TD算法的输入为:
- 所有的动作:$a=[a^1,a^2,…a^n].$
- 所有的观测:$o=[o^1,o^2,…o^n].$
- 第i个智能体的奖励:$r^i.$

- 第i个Critic网络的输出记为$q^i$,将他们发送给相应的Actor。
- 买个Agent训练自己的策略网络$π(a^i|o^i;\theta^)$,使用策略梯度。
- 去更新$\theta^i$,策略梯度算法的输入为$(a^i,o^i,q^i).$不需要知道其他Agent的策略和网络。