[强化学习]DDPG,TD3
DDPG
DDPG是基于AC架构的。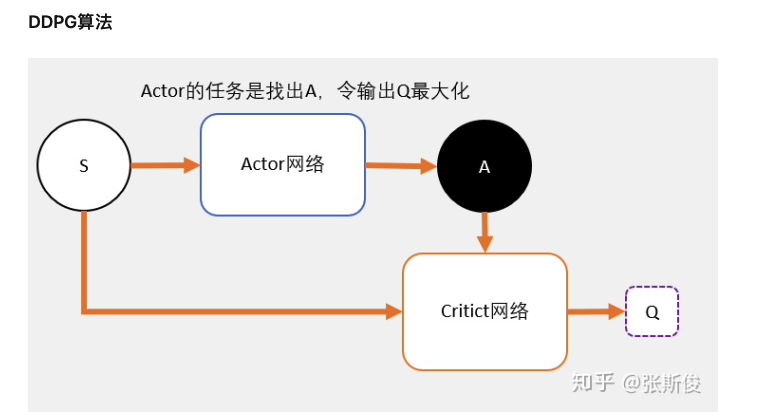
Critic
- Critic网络的作用是预估Q,但和AC中的Critic不一样,DDPG预估的是Q值不是V值。
- 注意Critic的输入有两个:动作和状态,需要一起输入到Critic中。
- Critic网络的loss其还是和AC一样,用的是TD-error。
Actor
- 和AC不同,Actor输出的是一个动作。
- Actor的功能是,输出一个动作A,这个动作A输入到Crititc后,能够获得最大的Q值。
- 所以Actor的更新方式和AC不同,不是用带权重梯度更新,而是用梯度上升。
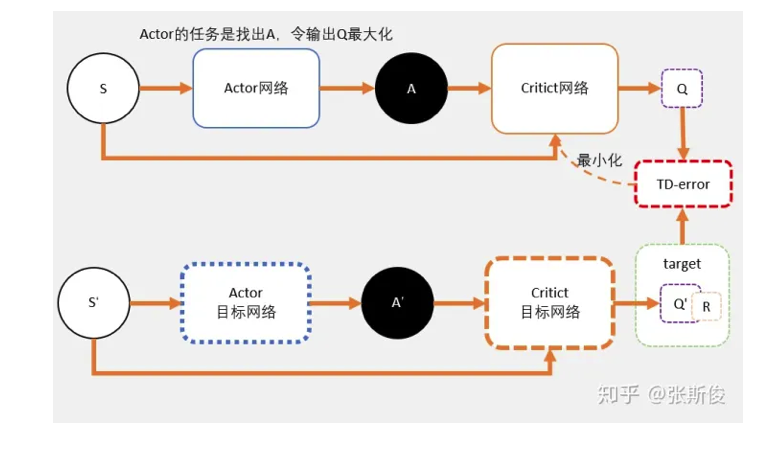
网络
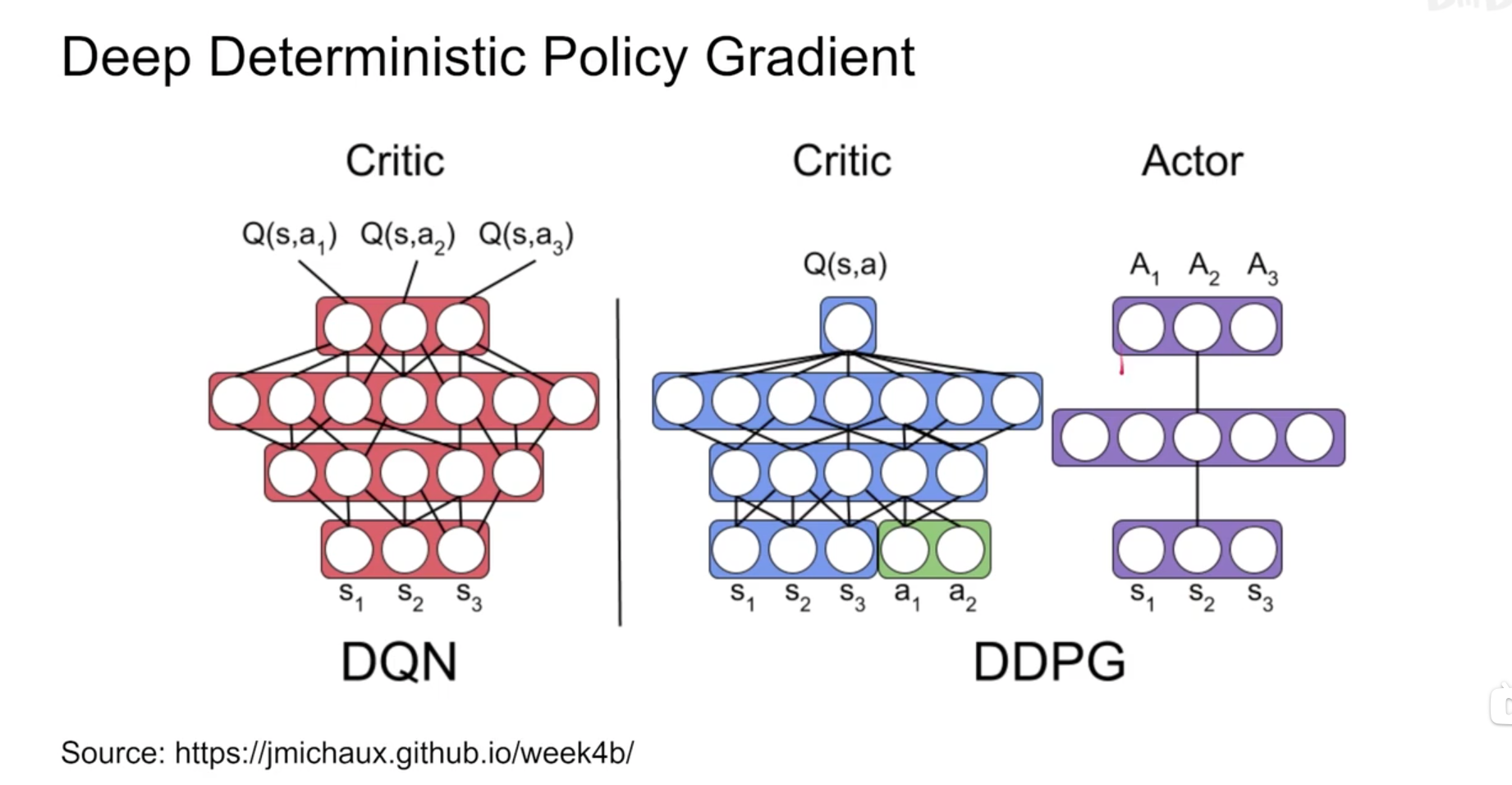
TD3
为了解决高估问题,是用来两套网络估算Q值,相对较小的那个作为更新的目标。这就是TD3算法的基本思路。
TD3的网络架构
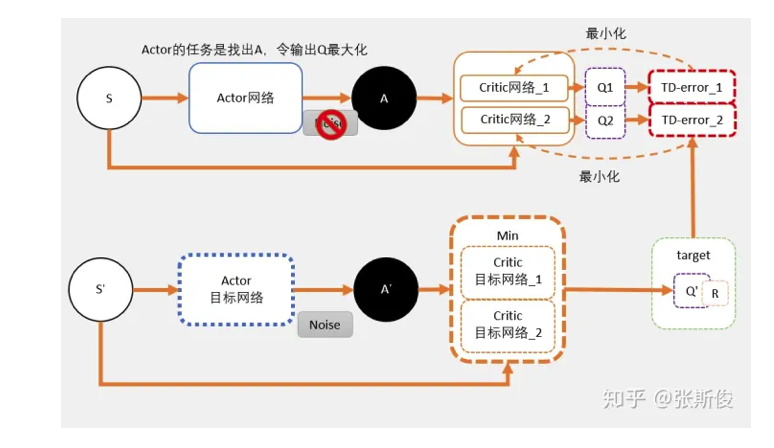
- TD3需要用到6个网络。Critic的框框变为了两个。
- 在目标网络中,我们估算出来的Q值会用min()函数求出较小值,以这个值作为更新的目标。
= 这个目标回更新两个网络 Critic网络_1和Critc网络_2。 - 可以理解为两个网络完全独立,他们只是用同一个目标进行更新。
- 剩余的就和DDPG一样了。过一段时间,把学习好的网络赋值给目标网络。
Critic部分的学习
- 只有在计算Critic的更新目标时,才会用到target network。其中包括了一个Policy network,用于计算$A^{‘}$;两个Q network,用于计算两个Q值:$Q1(A^{‘})$和$Q2(A^{‘})$.
- $Q1(A^{‘})$和$Q2(A^{‘})$取最小值$min(Q1,Q2)$代替DDPG的$Q(A^{‘})$计算更新目标,也就是说$target=min(Q1,Q2) * \gamma + r.$
- target将会是 Q_network_1 和 Q_network_2 两个网络的更新目标。
Actor部分的学习
- 对于actor来说,其实并不在乎Q值是否会被高估,他的任务只是不断做梯度上升,寻找这条最大的Q值。随着更新的进行Q1和Q2两个网络,将会变得越来越像。所以用Q1还是Q2,还是两者都用,对于actor的问题不大。
target policy smoothing regularization
TD3中,价值函数的更新目标每次都在action上加一个小扰动,这个操作就是target policy smoothing regularization。
为什么
在DDPG中,计算target的时候,我们输入s_和a_,获得q,也就是A。通过估算target得到另一点s,a,也就是另外一点B的Q值。
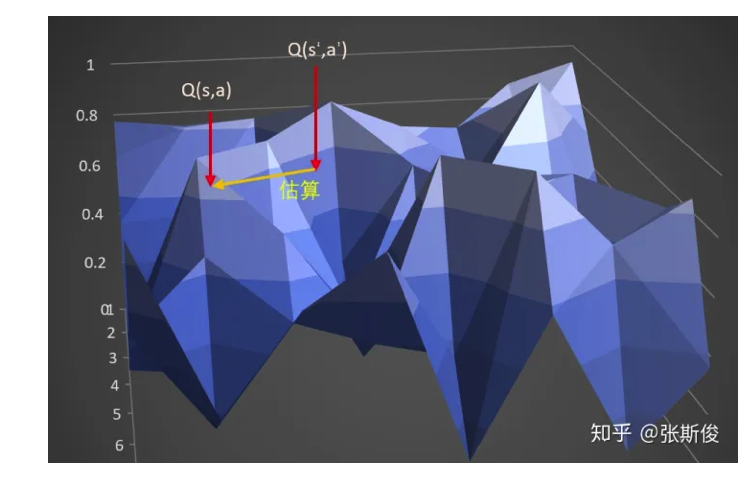
在TD3中,计算target的时候,输入s_到actor输出a后,给a加上噪音,让a在一定范围内随机。
这样的好处:当更新多次的时候,就相当于用A点附近的一小部分范围(准确来说是在s_这条线上的一定范围)去估算B,这样可以让那个B点的估计更准确,更健壮。
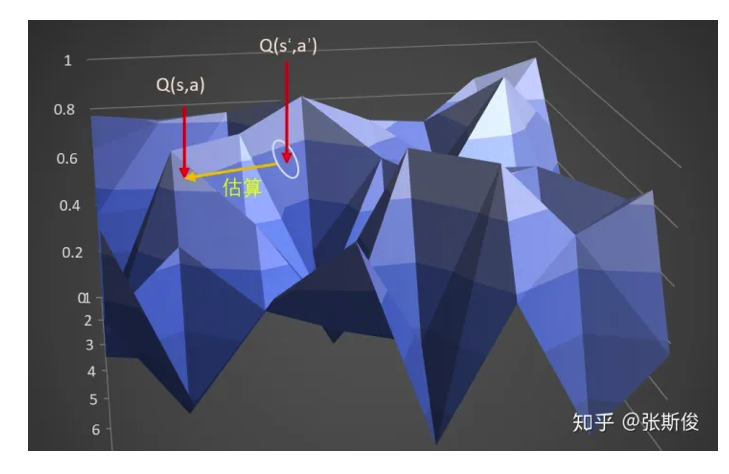
注意区别三个地方:
- 1.在跑游戏的时候,我们同样加上了了noise。这个时候的noise是为了更充分地开发整个游戏空间。
- 2.计算target的时候,actor加上noise,是为了预估更准确,网络更有健壮性。
- 3.更新actor的时候,我们不需要加上noise,这里是希望actor能够寻着最大值。加上noise并没有任何意义。