[JVM]JVM
跨平台原理
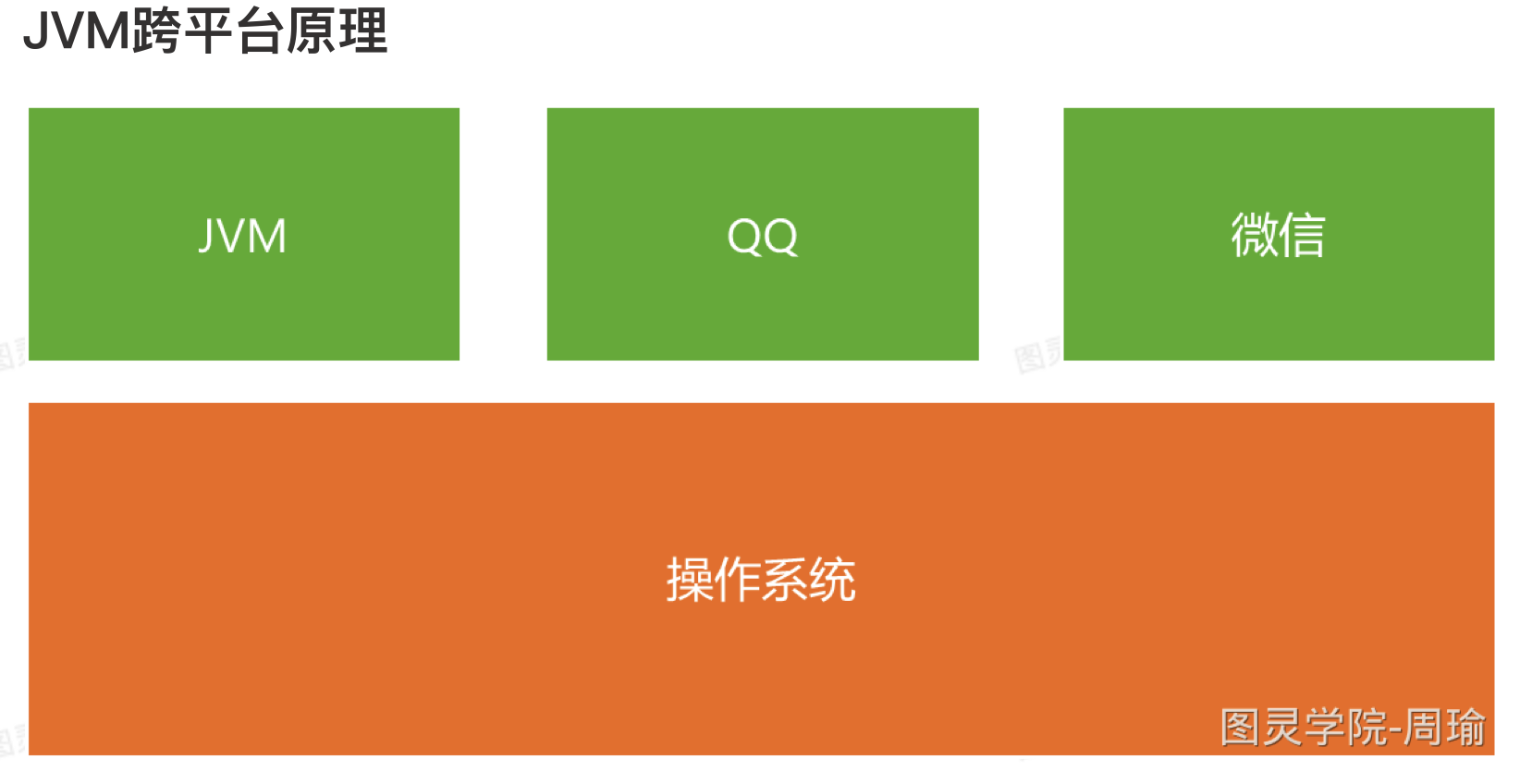
- JJVM就是⼀个运⾏在操作系统上的程序,JDK和JRE就是JVM的安装包,⽽我们运⾏java命令就能运⾏JVM,不管操作系统是什么,JVM运⾏起来后提供的功能是⼀样的,都是⽤来执⾏代码的。
- 不同操作系统上运行的JVM是不一样的,这就是JVM跨平台的本质。
- 我们写一份JAVA代码,编译成字节码,不同操作系统上的JVM都能运行字节码,相当于不同操作系统上的JVM屏蔽了不同操作系统的底层区别。
字节码的作用
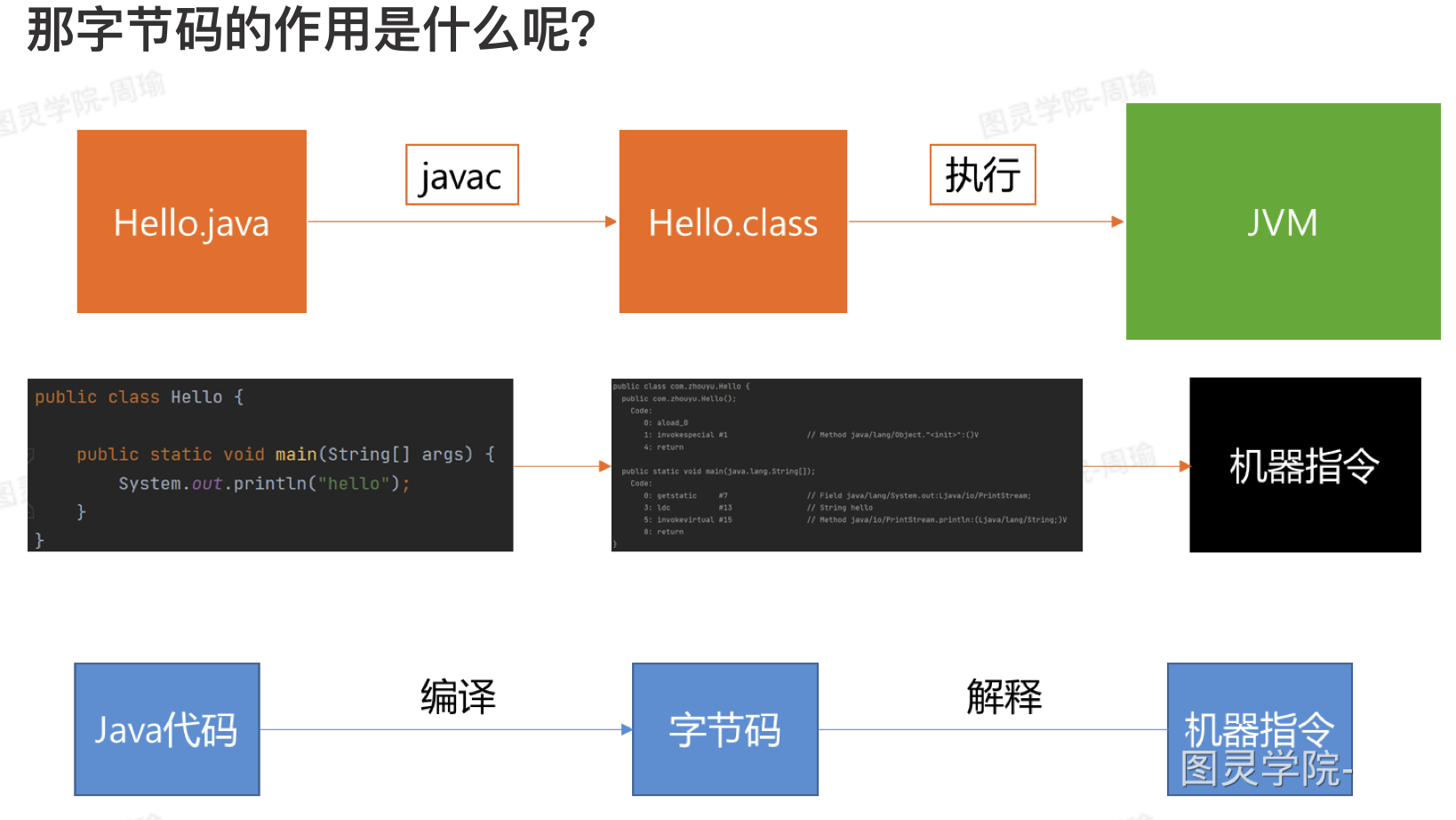
- JVM会逐行解释字节码。如果直接将Java代码翻译成机器指令,效率会大大降低。所以要提前对Java代码进行编译,编译成字节码,字节码再翻译成机器指令,效率比较高。Java其实是变异+解释二合一的语言。
JVM的整体结构
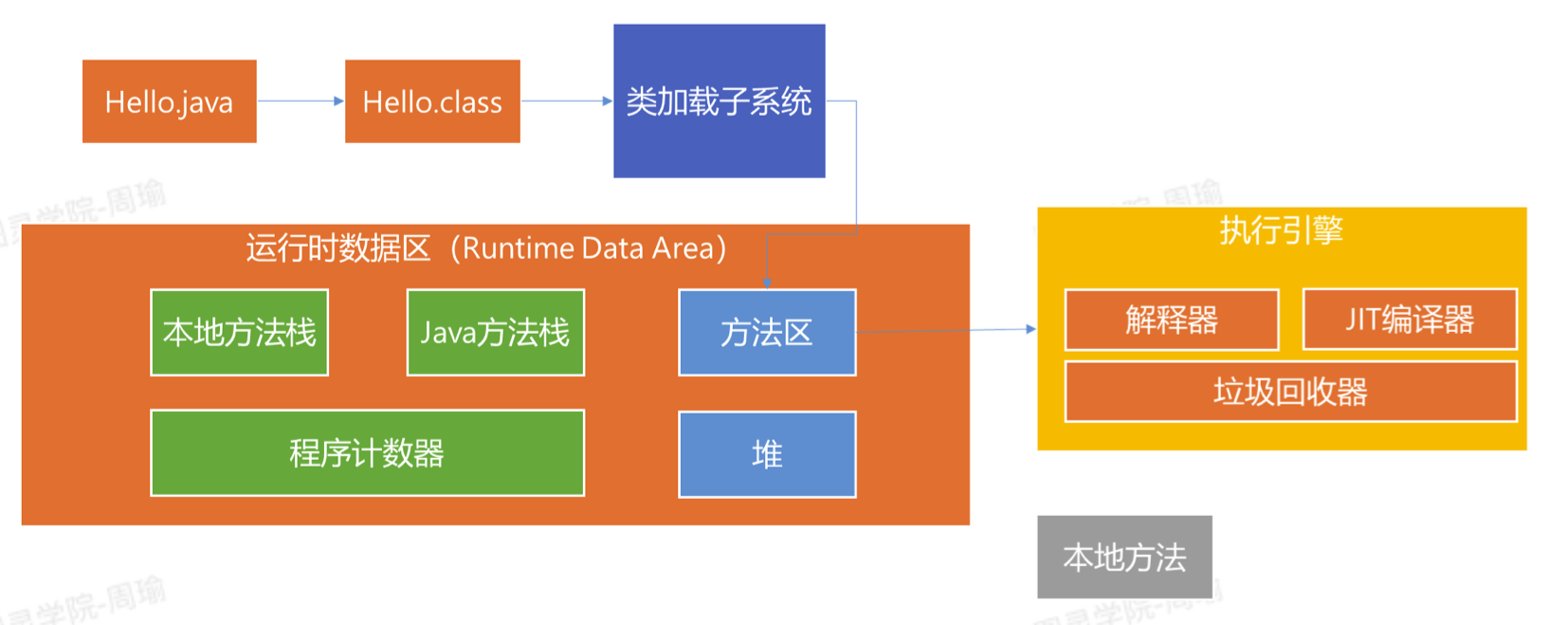
- 先将java文件编译成class文件
- 类加载器将class文件加载到方法区中
- 解析器逐行执行字节码。
- 每执行一个Java方法,就将方法存入Java栈中。
- 每执行一个本地方法,也就是native方法,就将方法存入本地方法栈总。
- 方法执行完后就从栈中移除
- 程序计数器用于记录带执行的吓一条字节码指令地址。
- 方法执行过程中产生的Java对象会存入堆中
- 垃圾回收器会回收已经没有被使用的Java对象。
- JIT编译器会在程序运行过程中发现热点代码,病编译成机器指令,从而提高执行效率。
类加载子系统
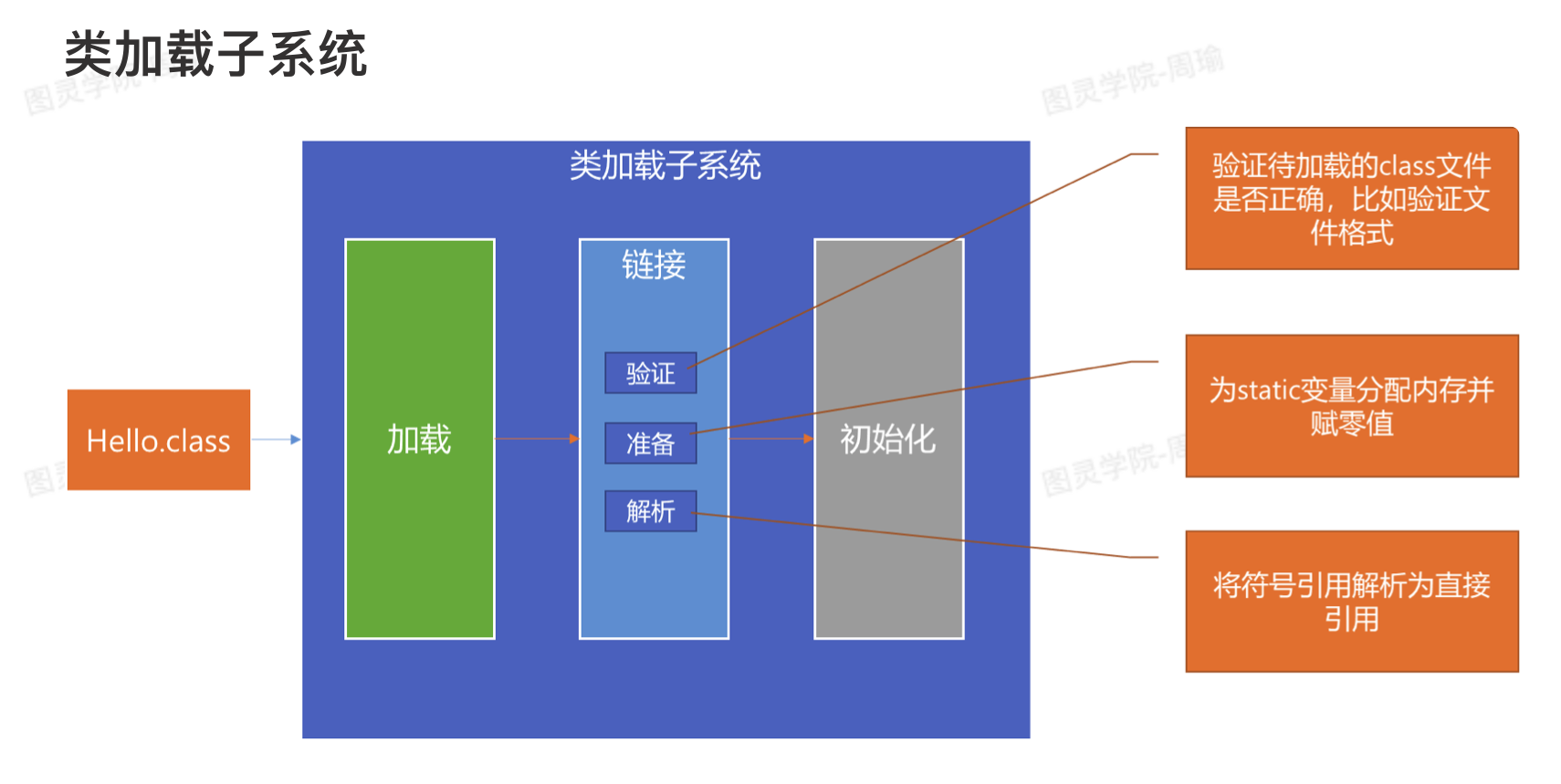
- 类加载子系统会将某个class文件加载到方法去中的内存空间中,可以理解为把class文件中字节码指令,读取到内存中。
- 验证阶段会验证到家在的class文件是否正确,比如验证文件格式。
- 准备阶段会为static变量分配呢困并赋零值。
- 解析阶段会将符号引用解析为直接引用,在一个字节码文件中,会用到其他类,而在字节码中只会存用到类的类名,而解析阶段就是会根据类名找到该类加载后再方法区中的地址,也就是直接印哟过,并替换符号引用。
- 初始化阶段会给static变量赋值,并执行static块。
类加载器的分类
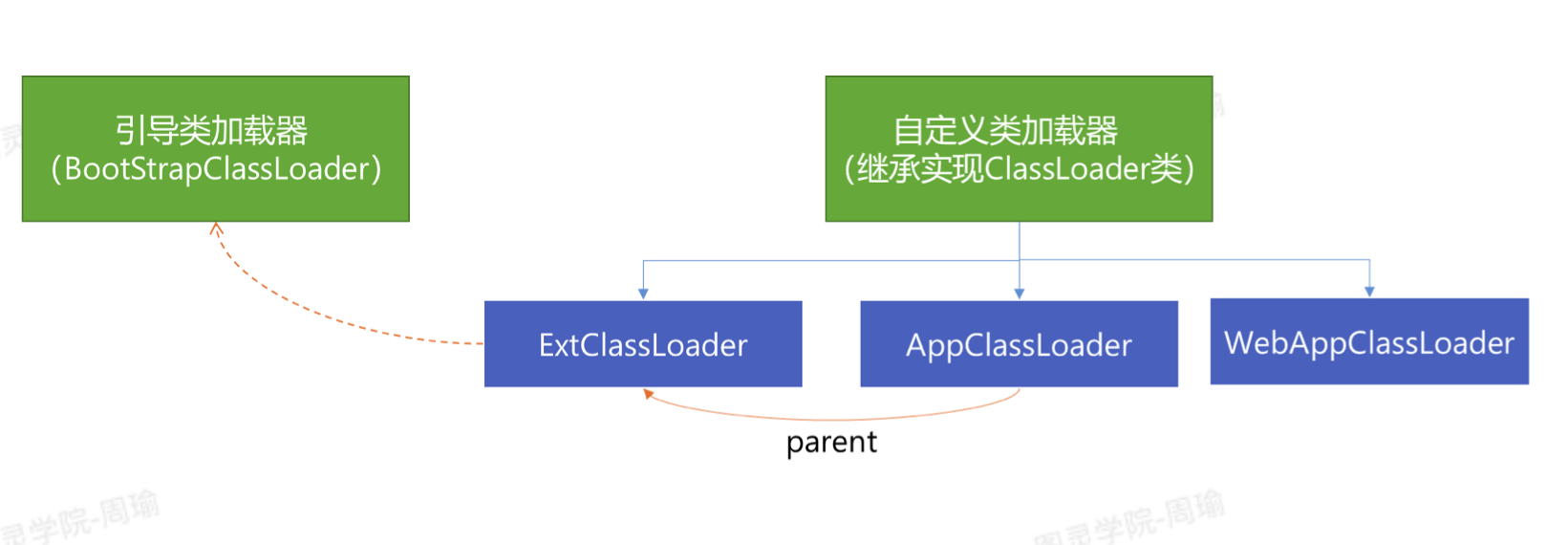
- JVM规范中,把类加载器分为两种:
- BootStrapClassLoader:由C和C++实现,负载加载jre/lib下的jar包中的类,比如rt.jar中的String类。
- 一种是继承了ClassLoader抽象类的加载器,是由Java语言实现的,比如:
- ExtClassLoader,加载jre/lib/ext目录下的类。
- AppClassLoader,加载目录为classpath所制定的目录。
- 其他自定义的,比如Tomacat中的WebAppClassLoader
通过继承URLClassLoader,最终间接继承了ClassLoader。
双亲委派
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34protected Class<?> loadClass(String name, boolean resolve)
{
throws ClassNotFoundException
synchronized (getClassLoadingLock(name)) {
//首先,检查类是否被加载了
Class<?> c = findLoadedClass(name); if(c==null){
long t0 = System.nanoTime();
try {
// parent有值则直接委托给parent去加载,否则委托给BootstrapCLassLoader去加载
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0)
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1)
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c; }
}
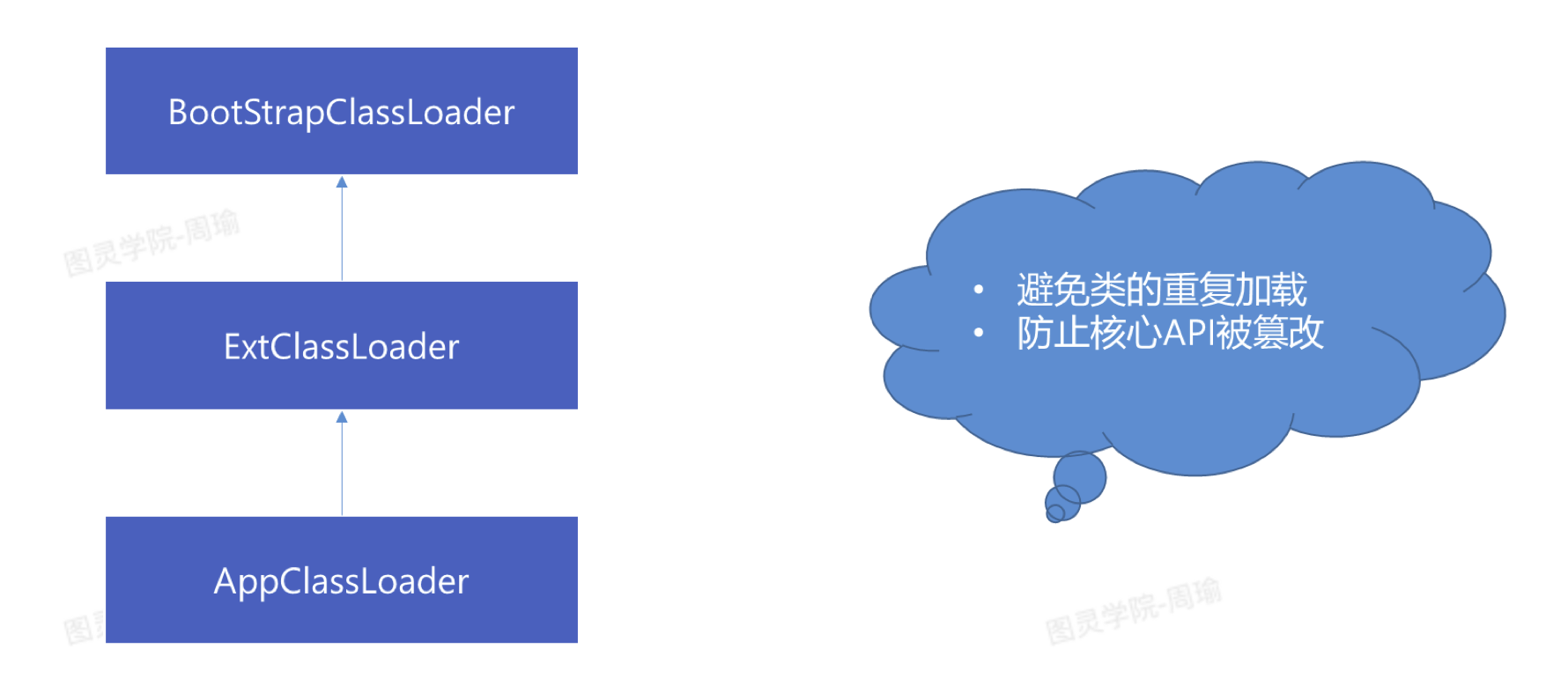
这段代码体现了双亲委派。
- 通过我们用AppClassLoader去加载一个类时,AppCLassLoader有一个parent属性指向了ExtClassLoader。会先委派给ExtClassLoader去加载。
- 而ExtClassLoader没有parent属性,所以会委派给BootStrapClassLoader去加载。
- 只有BootStrapClassLoader没有加载到,才会由ExtClassLoader去加载。
- 也只有ExtClassLoader没有加载到,才会有AppClassLoader去加载。
双亲委派的优点:
- 避免类的重复加载,如果一个类被ootStrapClassLoader加载过了,那么AppClassLoader就不会再加载到这个类类。
- 防止API被篡改,自定义一个java.lang.String类,但是我们是用不到这个类的,因为根据双亲委派始终加载的都是rt.jar中的hava.lang.String类。
Tomacat为什么要自定义加载器
为了进行类的隔离,如果Tomact直接使用AppClassLoader类加载类,那会出现如下情况:
- 1.应用A中有一个com.zhouyu.Hello.class
- 2.应用B中有一个com.zhouyu.Hello.class
- 3.虽然都叫做Hello,但是具体的方法、属性可能不一样。
- 4.如果AppClassLoader先加载了应用A中的hello.class
- 5.那么引用B中的hello.class就不可能再被加载了,因为名字一样。
- 6.如果就需要针对应用A和应用B设置个字单独的类加载器,也就是WebappClassLoader.
- 7.这样两个应用中的Hello.class都能被鸽子的类加载器所加载,不会冲突。
- 8.这就是Tomact为什么用自定义类加载器的核心原因,为了实现类加载的隔离。
- 9.JVM中判断一个类是不是已经被加载的逻辑是:类名+对于的类加载器实例。
运行时的数据区
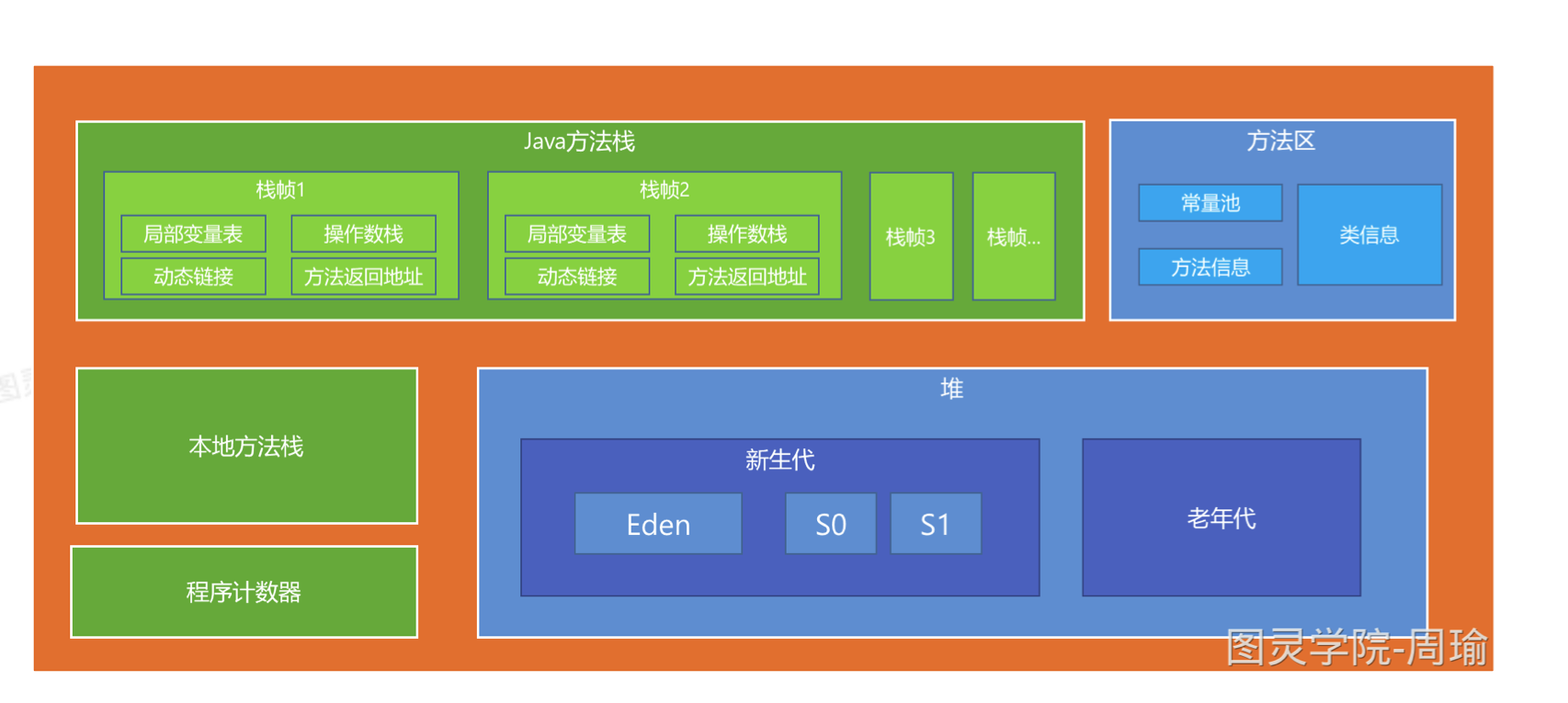
- 本地方法栈、Java方法栈、程序计数器时每个线程单独的区域。
- 方法区、堆区市所有线程共享的区域。
程序计数器
PC Register,程序计数器寄存器,简称为程序计数器:
- 1.是物理寄存器的抽象实现
- 2.用来记录待执行的吓一跳指令的地址
- 3.他是程序控制流的指示器,循环、ifelse、异常处理、线程恢复等都依赖它来完成。
- 4.解释器工作时就是通过它来获取下一条需要执行的字节码指令。
- 5.它是唯一一个在JVM规范中没有规定任何OutOfMemoryError情况的区域。
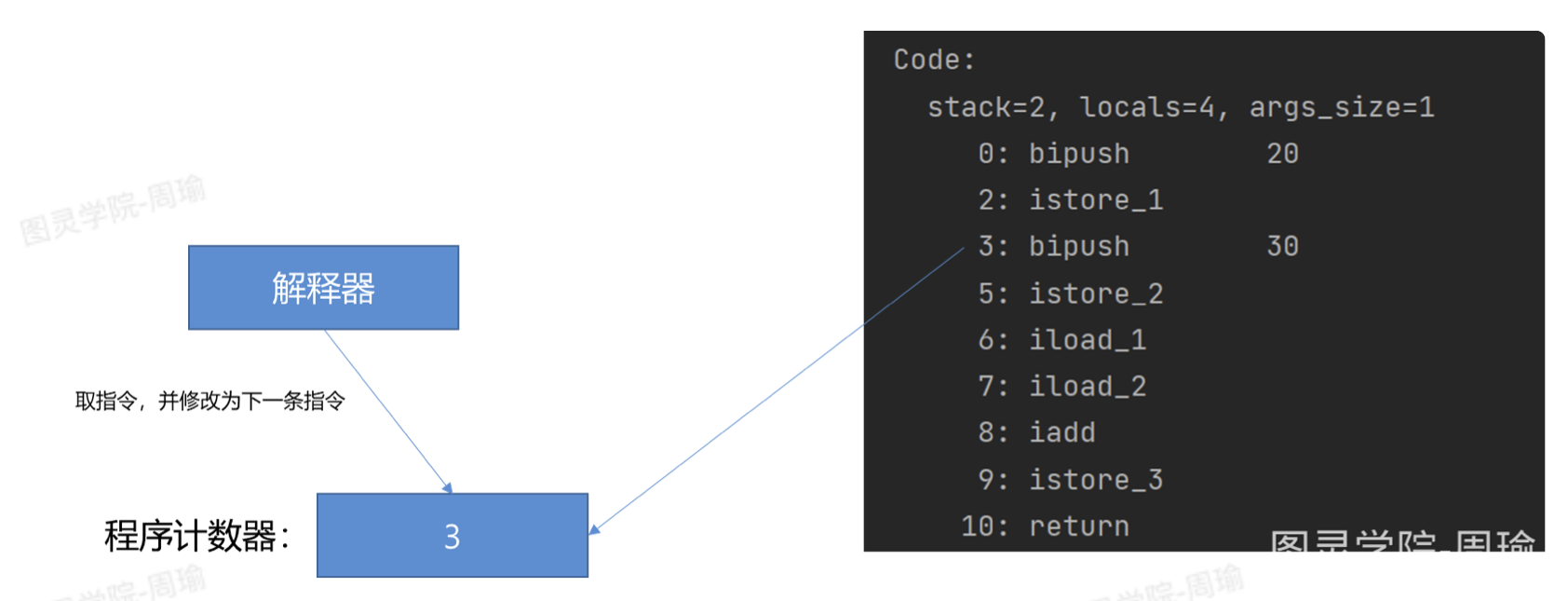
JVM的解释器在解释执行字节码指令时,会从程序计数器中取出接下来要执行的指令行号,并且将下一条指令的行号保存到程序计数器中,然后开始执行刚刚取出来的指令。
虚拟机栈
- 也可以被称为Java栈、Java方法栈(跟本地方法栈对比)
- 每个线程在创建时,都会创建一个虚拟机栈,栈内会保存一个个的栈帧,每个栈帧对应一个方法:
- 1.虚拟机栈时私有的
- 2.一个方法开始执行栈帧时入栈、方法执行完后对应的栈帧出栈,所以虚拟机不需要对应的垃圾回收。
- 3.虚拟机栈存在OutOfMenmoryError、以及StackOverflowError
- 4.线程太多,就可能会出现OutOfMenmoryError,线程创建时就没有足够的内存区创建虚拟机栈了。
- 5.方法调用层次太多,就可能出现StackOverflowError。
- 6.可以通过-Xss来设置虚拟机栈大小。
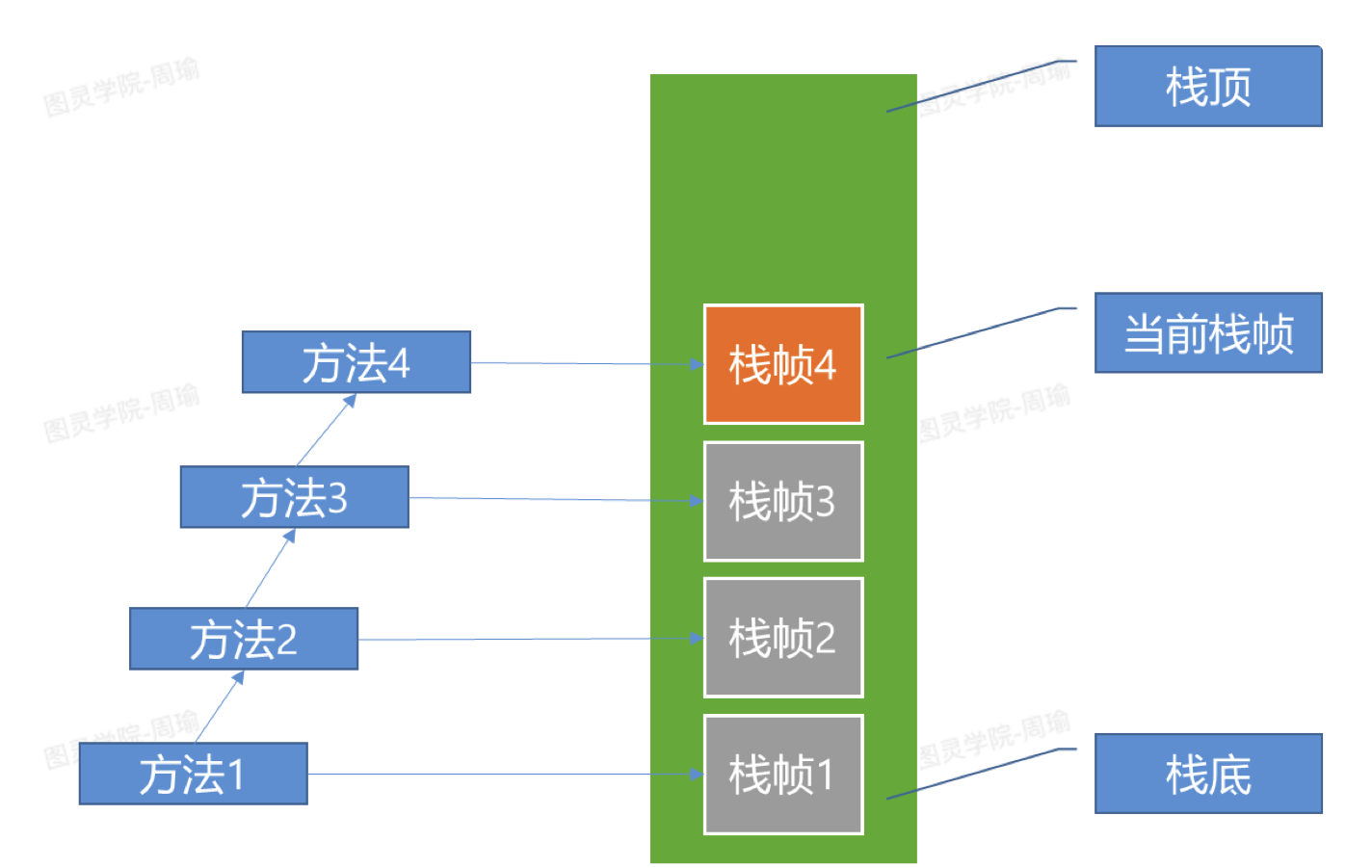
- 执行方法1时,会生成一个栈帧1入栈。
- 如果方法1中调用了方法2,那么又会生成一个栈帧2入栈。
- 如果方法2中调用了方法3,那么又会生成一个栈帧3入栈。
- 如果方法3中调用了方法4,那么又会生成一个栈帧4入栈。
- 方法4真正执行完或抛出异常后,对应的栈帧4就会出栈,并且会把方法的执行结果或者异常传给栈帧3以此类推,最后方法1执行完后,当前线程的虚拟机栈中就灭有东西了,最后线程也会退出。
栈帧
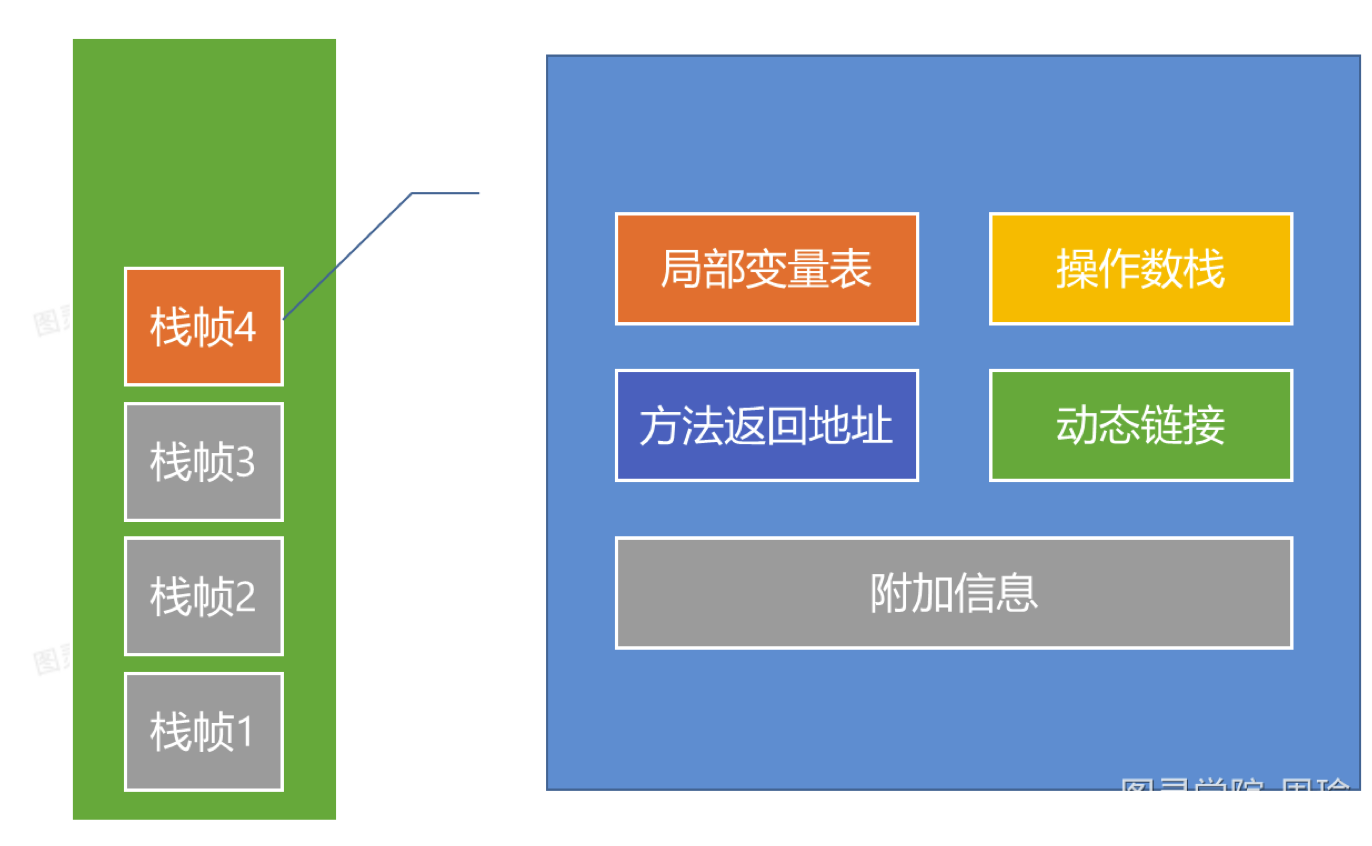
局部变量表
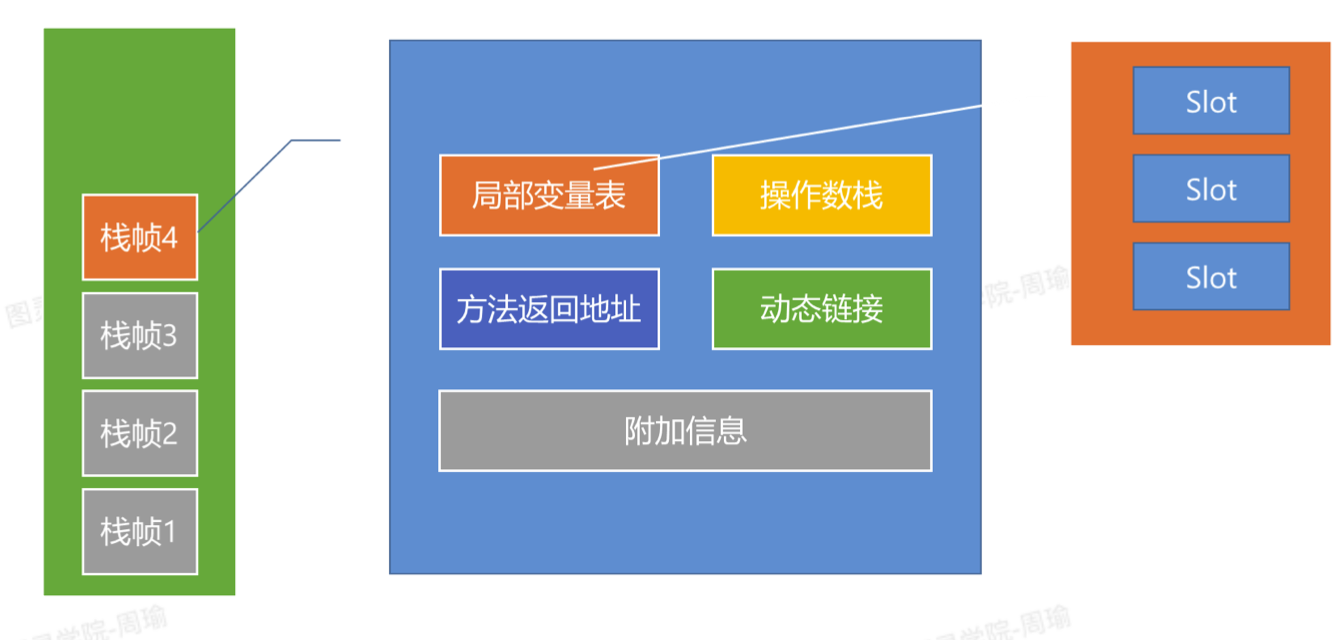
- 局部变量表local variables。其实就是列表,是数组的意思。主要用来保存方法参数和方法内的局部变量,要么是基本数据类型,要么是引用地址。
- 局部变量表所需的内存大小在编译器就确定下来了。根据参数类型和变量类型确定,可以在字节码中看到,不过字节码中的局部变量表中只存了局部变量的位置,没有存值。
- 局部变量表中基本的存储单位是Slot,每个Slot可以存储一个占32bit的值,像double类型的数字就需要两个Slot才能存,对象的引用地址也是存在Slot中的,占一个Slot。对应的字节码中就记录了局部变量表
1
2
3
4
5public static void main(String[] args) {
double d = 1.1f;
Object o = new Object();
int i = 3;
}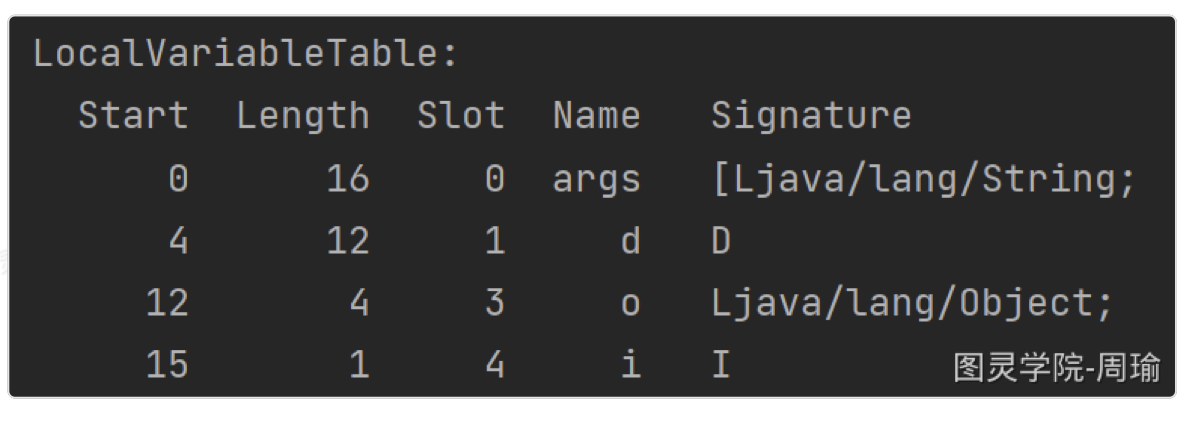
- 1.可以看到args是方法参数,占0个Slot
- 2.变量d是double类型,占1,2个Slot
- 3.变量o是一个对象,占第3个Slot,Slot中对象的引用地址
- 4.变量i是一个int类型,占第4个Slot。
因此,方法参数和局部变量越多,那么栈帧也就越大,也就越容易出现栈溢出,另外,局部变量表总的变量也是重要的垃圾回收根节点,只要被局部变量表直接或间接引用的对象就不会回收。
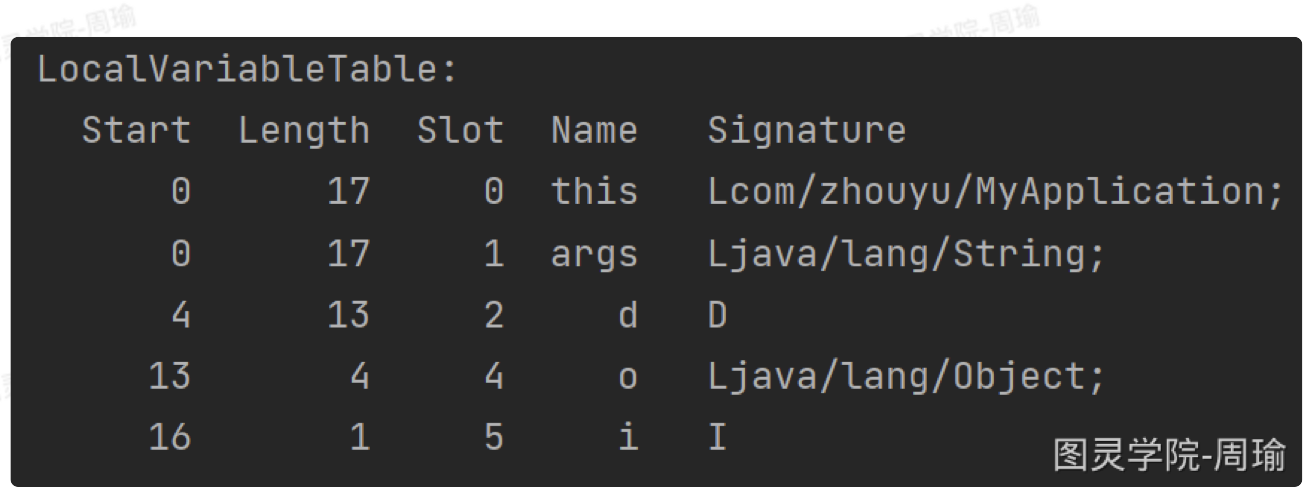
- 另外,如果方法不是static方法,那么局部变量的第0个Slot存的是this:
1
2
3
4
5public void test(String args){
double d = 1.1f;
Object o = new Object();
int i = 3;
}
操作数栈
操作数栈,OperandStack,也可以叫操作栈,也是栈帧的一部分,操作数栈是用来执行字节码指令过程中用来临时存数据并用来计算的。
本地方法栈
- 本地方法: native method,在Java定义的方法中,但由其他语言实现。
- 虚拟机栈存的是Java方法调用过程的栈帧,本地方法栈存的是本地方法调用过程中的栈帧。
- 也是线程私有的,也有可能出现OOM和SOF。
堆区

- JVM规范中所有的对象和数组都应该存放在堆中。
- 在执行字节码指令时,会把创建的对象存入堆中,对象对应的引用地址存入虚拟机栈中的栈帧中。
- 方法执行完后,刚刚所创建的对象并不会立马被回收,而要等JVM后台执行GC后,对象才会被回收。
我们可以通过:
- Xms:制定堆的初始化大小
- Xmx:制定堆的最大内存大小
一般会把-Xms和-Xmx设置为一样,这样JVM就不需要在GC后区修改堆的内存大小了,提高了效率。一般情况下,初始化内存大小=物理内存大小/64,最大内存大小大小=物理内存大小/4.
- 新生代一般存的是刚刚创建的对象。
- 老年代存的是一些经过多次垃圾回收后还活着的对象。
- 通过-XX:NewRatio参数来配置新生代和老年代的比例,默认为2,新生代占1,老年代占2,也就是新生代占堆区总大小的1/3.
一般是不需要调整的,只有明确知道存活时间比较长的对象偏多,那么就需要调大NewRatio,从而调整老年代的占比。
Eden:伊甸区,新对象都会先放到Eden区(除非对象的大小都超过了Eden区,那么就直接放进老年代)
- S0,S1:Surivivor0,Survivor1,也可以叫做from区,to区,用来存放MinorGC(YGC)后存放的对象。
默认情况下(Ednen:S0:S1)的比例大小关系为(8:1:1)。也可以通过-XX:SurvivorRatio来调整。
过程:
- 开始先放入Eden区,
- 一次YGC后,存活的对象进入S0区,
- 再次YGC后,存活的对象进入S1区
- 多次YGC后,存活的对象进入老年代区
Young GC/Minor GC:负责对新生代进行垃圾回收
- Old GC/Major GC:负责对老年代进行垃圾回收,目前只有CMS垃圾收集器会单独对老年代进行垃圾收集,其他垃圾收集器基本都是整堆回收的时候堆老年代进行垃圾收集。
- Full GC:整堆回收,也会对堆方法区进行垃圾回收。
- Eden区满了之后,就会进行YGC,YGC时会STW(Stop The World),会占停用户线程,YGC执行频率一般比较高,但是执行的速度比较快。
老年代满了之后,就会触发Full GC,一般会在Full GC之前执行一次YGC,Full GC也会STW,并且速度较慢,所以要尽可能避免Full GC,如果Full GC后,内存还是不足,那么就会报OOM了。
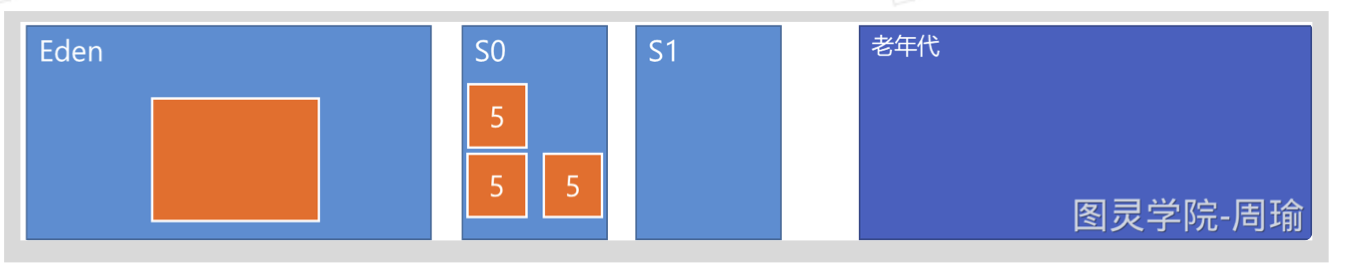
特殊情况1:如果TGC后,Eden区又存活对象,需要保存到S0区,但是S0剩余空间不够,那么这个对象会直接放到老年代。
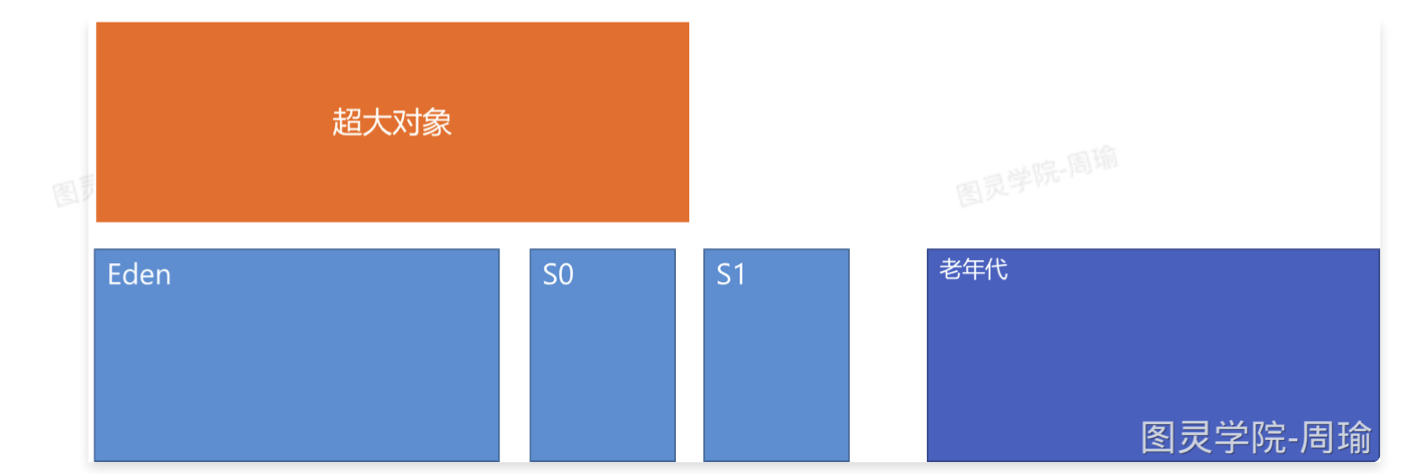
特殊情况2:如果有一次超大对象,比Eden区的范围都要大,会直接放到老年代,如果老年代放不下,会进行FGC,FGC后如果老年代放不下就回报OOM。
为什么要进行垃圾回收
垃圾是指在JVM中没有任何引用指向它的对象,如果不清理这些垃圾对象,那么它们就一直占用着内存,而不能给其他对象使用,最终垃圾对象越来越多,就会出现OOM。
引用计数法
每个对象都保存一个引用计数器属性,用户记录对象被引用的次数。
- 优点:实现简单,计数器为0则表示是垃圾对象
- 缺点:
- 需要额外的空间来存储计数器。
- 需要额外的时间来维护引用计数器。
- 最严重的问题:无法处理循环引用的问题。假设两个对象一直相互引用,计数器就一直是1,但又没有其他对象来引用这两个对象(实际是垃圾对象)。
可达性分析法
会以GC Roots作为起始点,然后一层一层找到所引用的对象,被找到的对象就是存活对象,那么其他不可达的对象就是垃圾对象。
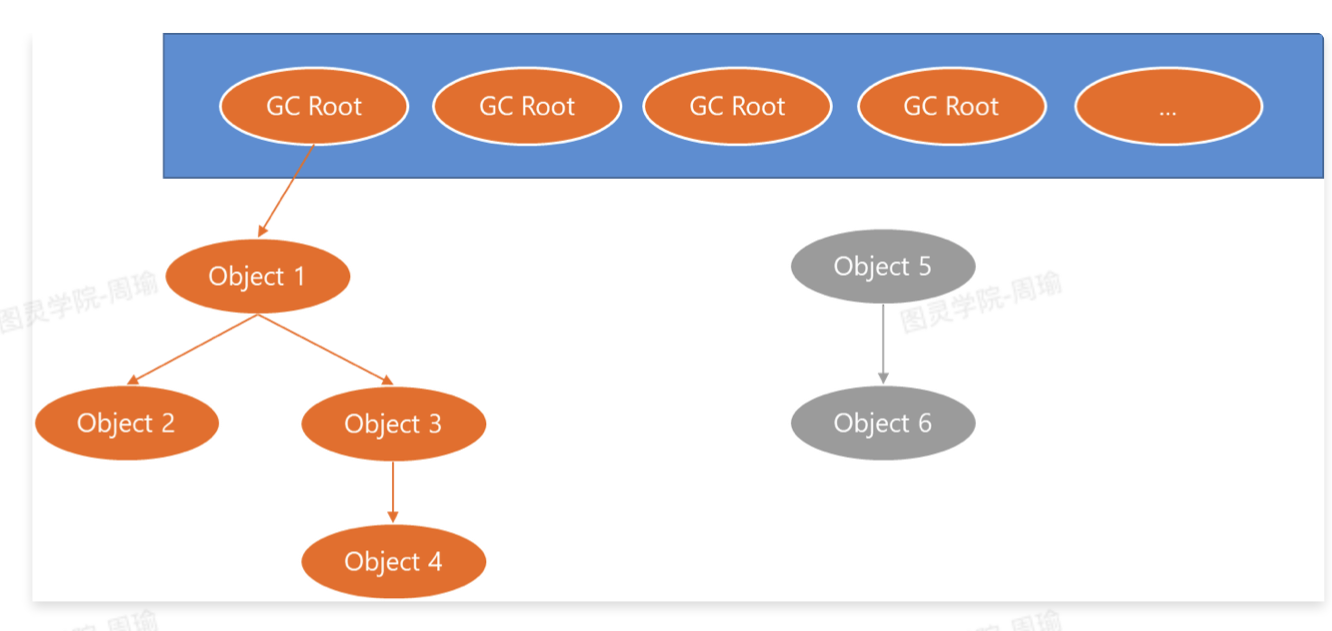
- GC Roots包括哪些:
- 线程中虚拟机栈中正在执行的方法中方法参数、局部变量所对应的对象引用。
- 线程中本地方法中正在执行的方法中方法参数、局部变量所对应的对象引用。
- 方法区中保存的类信息中静态属性所对应的对象引用。
- 方法区中保存的类信息中常量属性所对应的对象引用。
回收算法
标记-清除算法
找到垃圾对象怎么进行回收。
一种非常基础和常用的垃圾回收算法,针对某块内存空间,比如新生代、老年代,如果可用内存不足后,酒会STW,暂停用户线程的执行,然后执行算法进行垃圾回收:
- 1.标记阶段:从GC Roots开始遍历,找到可达对象,并在对象头中进行记录。
2.清楚阶段:堆内存空间进行线性便利,如果发现对象投中没有记录是可达对象,则回收他。
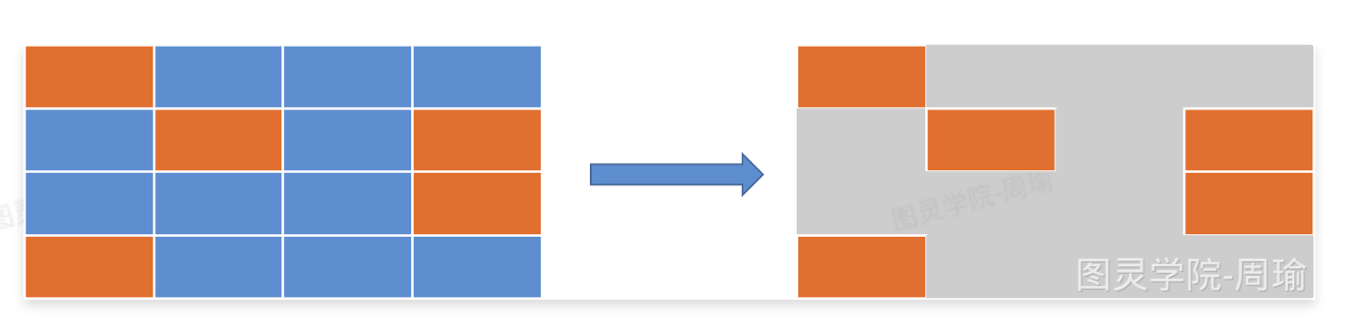
缺点:
- 效率不高
- 内存碎片:会产生一块一块的小内存,导致无法使用。
优点:思路简单
复制算法
将内存空间分为两两块,每次只使用一块,在进行垃圾回收时,将可达对象复制到另外没有被使用的内存块中,然后再清楚当前内存卡中的所有对象,后续再按同样的流程进行垃圾回收,交换着来。
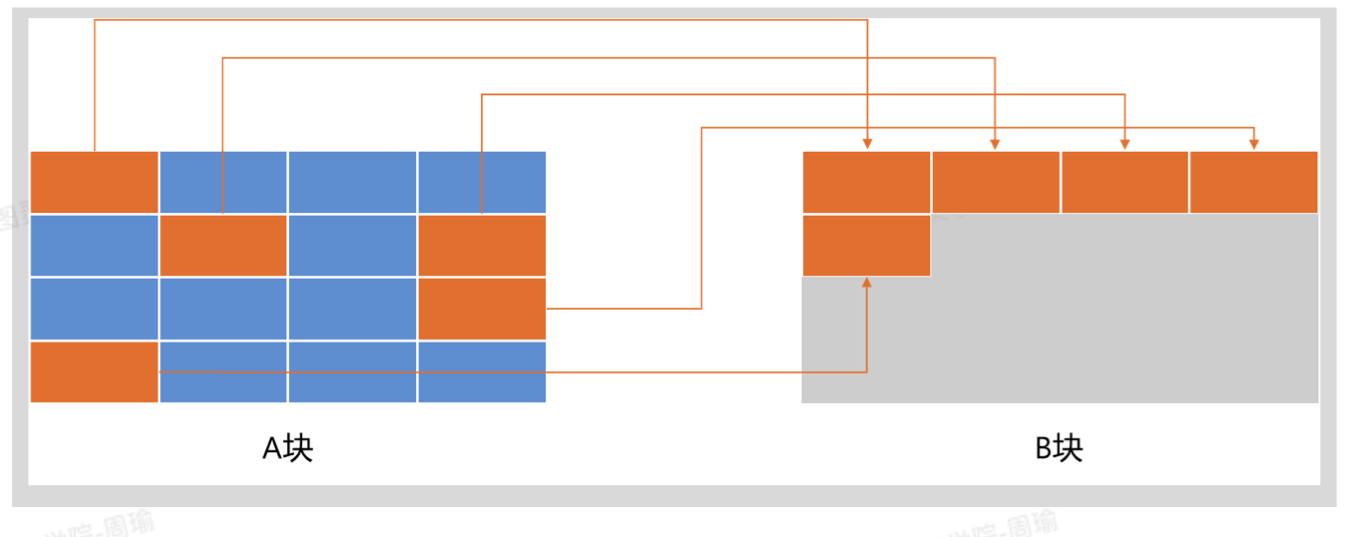
- 优点:
- 1.没有标记和清楚阶段,通过GC Roots找到可达对象,直接复制,不需要修改对象头,效率高。
- 2.不会出现内存碎片。
- 缺点:
- 1.需要更多的内存,始终有一半的内存空闲。
- 2.对象复制后,对象存放的内存地址发生了变化,需要额外的时间修改栈帧中记录的引用地址。
- 3.如果可达对象比较多,垃圾对象比较少,那么复制算法的效率就会比较低,所以垃圾对象多的情况下,复制算法比较合适。
标记-整理算法
- 第一阶段和标记-清除算法一样,从GC Roots找到并标记可达对象。
- 第二阶段将所有存活对象移动到内存的一端。
- 最后清理边界外所有的空间。

相当于标记-清除算法执行完一次之后再进行一次内存整理。 - 优点:
- 1.不会出现内存碎片。
- 2.也不需要利用额外的空间。
- 缺点:
- 1.效率相对较低。
- 2.也需要修改栈帧中的引用地址。
回收算法比较
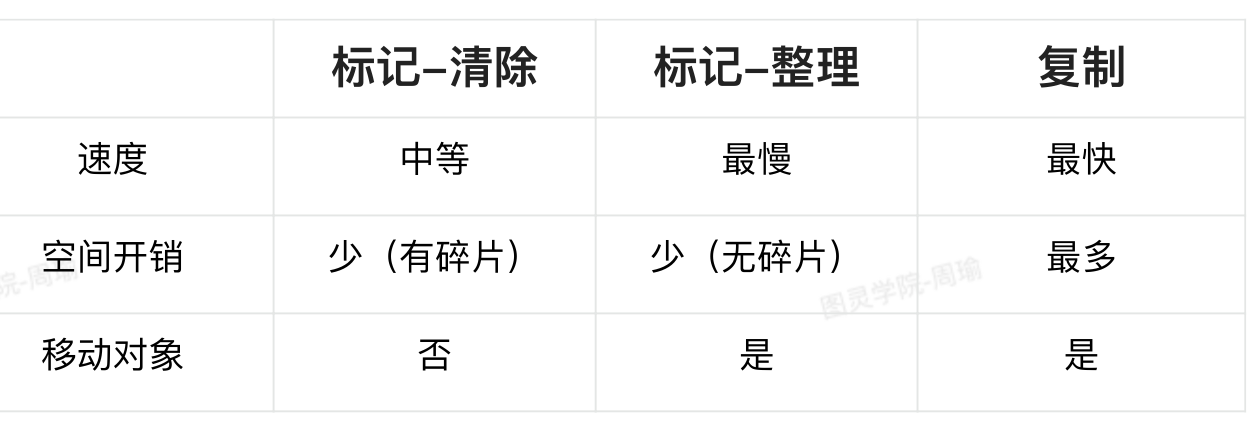
分代收集算法
- 不同的对象存活时间是不一样的,也就可以针对不同的对象采取不同的垃圾回收算法。
- 默认几乎所有的垃圾收集器都是采用分代收集算法进行垃圾回收的。
- 我们会把堆分为新生代和老年底代:
- 1.新生代中的对象存活时间比较短,那么就可以利用复制算法,它适合垃圾对象比较多的情况。
- 2.老年代中的对象存活时间比较长,所以不太适合用复制算法,可以哟过标记-清除或标记-整理算法,比如:
- CMS垃圾收集器采用的就是标记-清除算法。
- Serial Old垃圾收集器采用的就是标记-整理算法。
常用的垃圾收集器
| 回收器 | 串/并行 | 描述 | 新生。老年代 | 算法 | 备注 |
|---|---|---|---|---|---|
| Serial GC | 串行 | 工作线程暂停,一个线程进行垃圾回收 | 新生代 | 复制算法 | |
| Serial Old GC | 串行 | 工作线程暂停,一个线程进行垃圾回收 | 新生代 | 标记-整理 | |
| ParNew GC | 并行 | 工作线程暂停,多个线程进行垃圾回收 | 新生代 | 复制算法 | Serial GC的多线程版 |
| CMS GC | 并行 | 用户线程和垃圾回收线程同时进行 | 老生代 | 标记-清除算法 | 低暂停 |
| Parallel GC | 并行 | 工作线程暂停,多个线程进行垃圾回收 | 新生代 | 复制算法 | 和ParNew相比,能动态调整内存分配情况,JDK8默认 |
| Parallel Old GC | 并行 | 工作线程暂停,多个线程进行垃圾回收 | 老年代 | 标记-整理算法 | 替代串行的Serial Old GC |
| G1 | 并行 | 用户线程和垃圾回收线程同时进行 | 整堆 | 分区算法 | 在延迟可控的情况下尽可能提高吞吐量 |
| ZGC | 并行 | 用户线程和垃圾回收线程同时进行 | 整堆 | 分区算法 | STW的时间不超过1ms,且不会随着堆的大小增加而增加 |
- -XX:+PrintCommandLinelags,查看使用的垃圾收集器。
- -XX:+UserSerialGC,制定使用Serial GC和Serial Old GC.
- XX:+UseParNewGC,指定新生代使用ParNew GC,-XX:+UseConcMarkSweepGC,指定老年代使用CMS GC
- -XX:+UseParallelGC,指定新生代使用Parallel GC, -XX:+UseParallelOldGC,指定老年代使用Parallel Old GC,这两个配置一个,另一个自动激活
Parellel Gc 和 Parallel Old GC
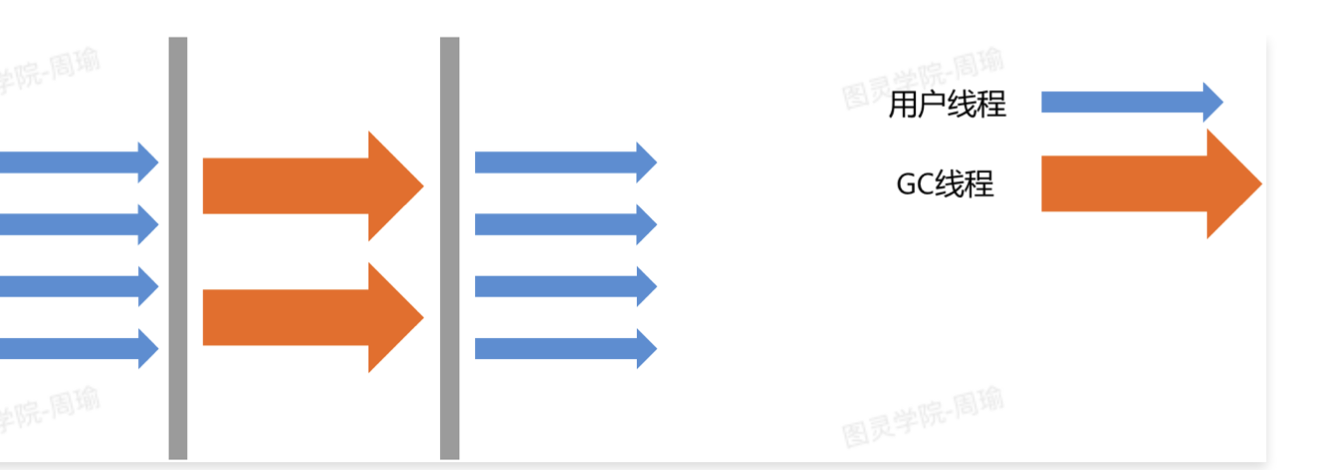
在一次垃圾收集过程中,会进行一次STW,并且会有多个线程同时进行垃圾回收。
CMS
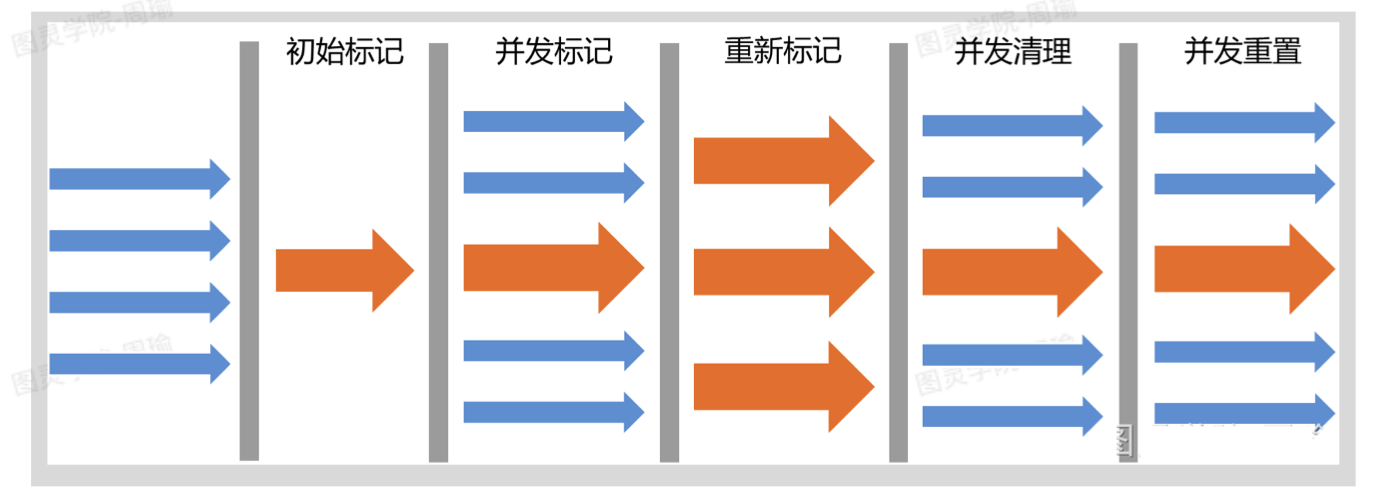
CMS整个垃圾收集过程更长,但是STW的时间变短,在垃圾收集过程中大部分时间用户线程还在执行,所以用户体验更好了,但是吞吐量变低。(单位时间内执行的拥护线程更短了)
- 初始标记:
- STW,暂停所有工作线程
- 然后标记出GC Roots能直接可达的对象
- 一旦标记完,就回复工作线程继续执行
- 这个阶段比较短
- 并发标记:
- 从上一个阶段标记出的对象,开始遍历整个老年代,标记出所有的可达对象。
- 耗时会比较长
- 但是不需要STW,用户线程与垃圾收集线程一起执行
- 三色标记
- 重新标记:
- 上个阶段标记的对象,可能有误差,需要进行修正。
- 需要STW,但是时间也不是很长。
- 增量更新
并发清除:
- 删除垃圾对象
- 由于不需要移动对象,这个阶段也可以和用户线程也一起执行,不需要STW
如果在并发标记、并发清理的过程中,由于用户线程同时执行,如果有新对象要进入老年代,但是空间又不够,就会导致“concurrent mode failure”,此时就需要Serial Old做一次垃圾收集,就会做一次全局的STW。
并发清理过程中,可能产生新的垃圾,这些就是“浮动垃圾”,只能等到下一次GC时来清理。
由于采用表情-清除,所以会出事内存碎片,可以让JVM在执行完后再做一次整理。也可以指定多少次GC后来做整理。默认时0,即每次GC都会整理。
G1
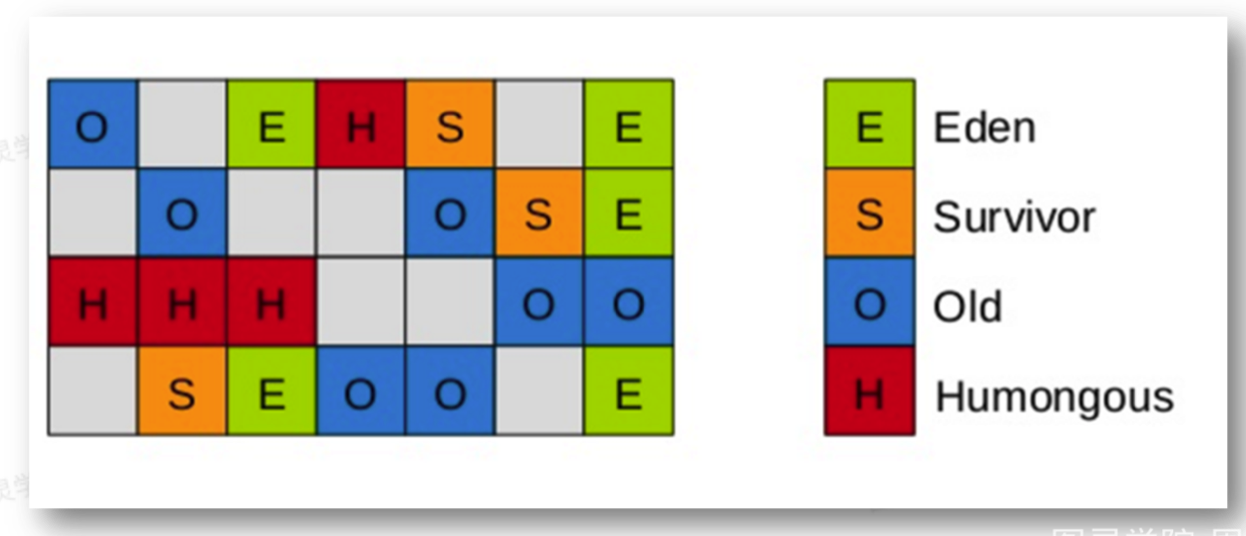
把空间分为regin,每一个方块叫做regin,堆内存会分为2048个regin,每个regin的大小等于堆内存/2048。分成Eden,S0,S1,老年代区,只不过空间不是连续的。Humongous区是专门用来存放大对象的(如果一个对象大小超过了一个regin的50%,那么就是大对象)。
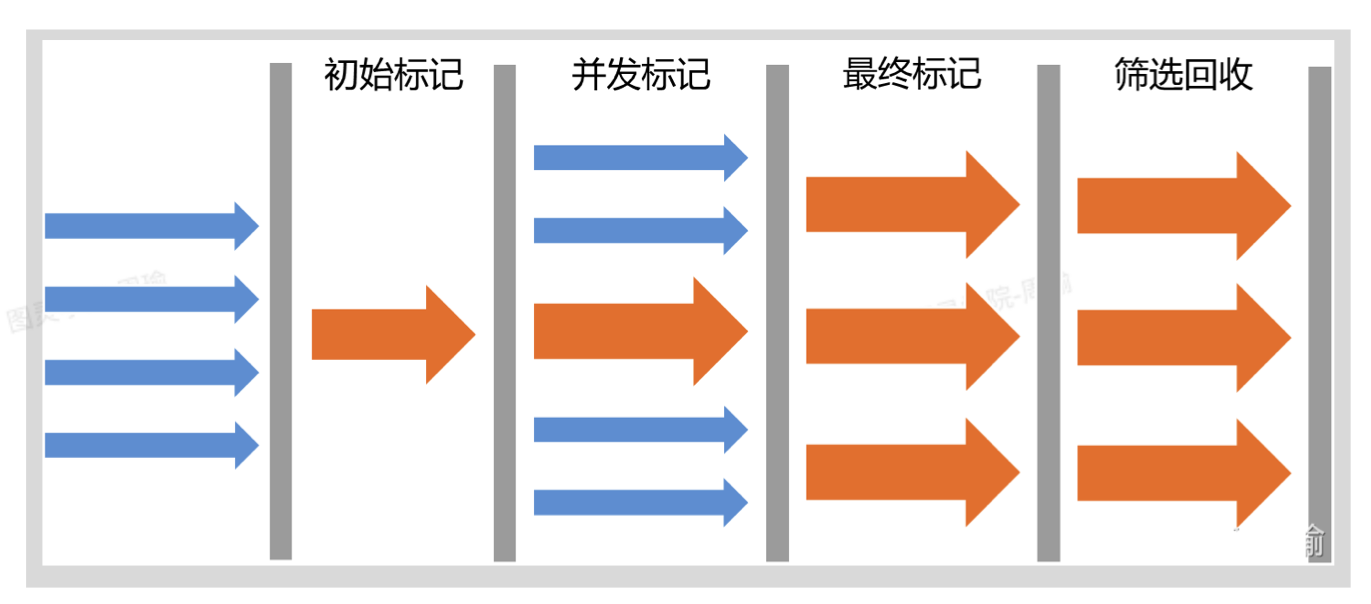
- 初始标记(同CMS):
- STW,暂停所有工作线程
- 然后标记出GC Roots能直接可达的对象
- 一旦标记完,就回复工作线程继续执行
- 这个阶段比较短
- 并发标记(同CMS):
- 从上一个阶段标记出的对象,开始遍历整个老年代,标记出所有的可达对象。
- 耗时会比较长
- 但是不需要STW,用户线程与垃圾收集线程一起执行
- 三色标记
- 重新标记(同CMS):
- 上个阶段标记的对象,可能有误差,需要进行修正。
- 需要STW,但是时间也不是很长。
- 增量更新
筛选回收(类CMS):
- 需要STW,来清除垃圾对象。
- 需要制定GC的STW停顿的时间,所以可能并不会回收掉所有垃圾对象,默认200ms。
- 采用复制算法,不会产生碎片。(会把某个region里的垃圾对象复制另外空间region区域,比如相邻的)
Young GC:Ednen区满,就会触发G1的YoungGC,对Eden区进行GC
- Mixed GC:老年代达到了指定的百分比,回收所有的新生代以及部分老年代,以及大对象区。
- Full GC:在进行Mixed GC过程中,采用的复制算法,如果复制过程中内存不够,则会触发Full GC,会STW,并采用单线程进行标记-整理算法进行GC,相当于一次Serial GC。